

Improve Credit Decisions With an Expanded View of Risk
Every lender is different, but many struggle with similar challenges: How — and when — to extend more competitive offers and approve a wider range of credit applicants while managing risk exposure. Traditional methods of credit risk decisioning can leave valuable pieces of the picture out of view. It’s time to rethink the data and insights your lending organization uses to assess creditworthiness.
By augmenting existing credit risk assessment strategies with powerful, predictive and proven alternative data insights, your lending team can gain a better understanding of customer credit risk to:
- Expand the addressable lending market
- Assess thin- and no-file applicants
- Segment risk among prime and near-prime applicants
- Inform more competitive offers
- Say yes with more confidence

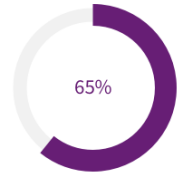
1. Aite Group Q4 2020 and Q1 2021 North American Consumer Lending Survey
Start approving more customers while managing risk tolerance thresholds with alternative credit solutions.
Shifting Dynamics Introduce New Blind Spots
This makes it ever more crucial to evaluate new strategies for consumer and small business credit risk assessment.
It feels like an impossible task — especially given the increasing pressure for growth, declining tolerance
for financial losses and mounting regulatory scrutiny.
Many Dynamics Cloud the View of Opportunity and Risk:
- Lending accounted for the largest area of growth — 25% — among fintech platforms from 2020 to 2021.2
- Fintech small business quarterly loan originations rose from approximately $121 million (2013) to $2 billion (2018).3
2 McKinsey & Company, “How U.S. customers’ attitudes to fintech are shifting during the pandemic,” December 17, 2020
3 Federal Reserve Bank of Cleveland, The Rise of Fintech Lending to Small Businesses: Businesses Perspectives on Borrowing, March 2021
4 Congressional Research Service, Financial Inclusion and Credit Access Policy, Updated October 24, 2019

Alternative Data Insights Shed Light on What Traditional Credit Data May Miss
Creditworthiness is shaped by many factors that push a consumer’s financial trajectory upward or downward. These range from lifestyle patterns over time to short-term recoverable events. Alternative data models add meaningful dimensions to this financial view — making note of behavioral predicators such as education history, address stability, professional licenses, asset ownership and more. These kinds of insights increase the reliability of customer credit risk assessment because they allow you to see shifts that impact creditworthiness sooner. Identify promising credit-invisible applicants — while also getting a heads up on prime applicants who are struggling.
Unlock Portfolio Growth While Managing Risk Tolerance Thresholds
The Ability To Better Decipher Between Likely Profitable and Risky Consumers
Is Pivotal. But the Differences May Be Nuanced and Require a Wider Scope
Than Just Repayment History, Bankcard Utilization or 30-Day Delinquencies.
Credit Risk Assessment With a Competitive Edge
New innovations in credit and lending — think challenger banks and fintechs — give consumers and small businesses more choices and reasons to shop for the best rate. With alternative data in your toolbox, you have insight that can help you win those customers over. Not only by crafting highly competitive offers — but also attracting those potentially creditworthy customers other lenders may ignore.
See opportunity where others see risk

Differentiate the “red carpet” prospects from those warranting less-optimal terms

Initiate more predictive risk assessment by pinpointing positive or negative events sooner

Approve more applicants while managing risk tolerance thresholds
Build Competitive Offers Across the
Consumer Credit Spectrum
of customer credit risk decisions. Maximize approval rates,
manage risk tolerance thresholds.
Boost Profitability in Small Business Lending
with Stronger Risk Assessment
and business owner and/or authorized representative. Better understand the health
of the business with an economic view of those leading it.
We Pioneered the Field of Alternative Credit Data: A Critical Path to Financial Inclusion
Using alternative data solutions, you can surface these critical insights to drive more effective financial inclusion strategies. These are the tools that tear down barriers to economic access. Close the gaps of data and opportunity. Maintain rigor, yet champion wider access to credit. Everybody wins.
5. FinRegLab, The Use of Cash-Flow Data in Underwriting Credit, July 2019
6. Federal Reserve Banks, Small Business Credit Survey: 2021 Report on Nonemployer Firms

LexisNexis® Risk Solutions Provides Fresh Insights on 90%
of Thin-File and No-File Consumers.
Data Sources Differ in Quality. Grow Your Business on Best-In-Class Credit Risk Solutions

We leverage best-in-class linking technology
Bringing together vast data sources

To create a single picture of a consumer or business and the analytics insights to guide you
A Commitment to Innovation
with patented analytics, proven expertise, and near real-time insight into consumer behavior.
Credit Risk Assessment Solutions
From consumer to small business lending, choose the alternative credit risk solution that can help you score more thin- and no-file applicants, improve lending decisions on the margin, and responsibly issue the improved offers to prime consumers that needed to win their business.
Consumer Credit Risk Assessment
of life changes that shape their economic trajectory.
Small and Mid-Sized Business Credit Risk Assessment
an enhanced picture of a business and a more informative
view of its financial health.
Let’s Talk About Refining Your Credit Assessment Strategies
assessment — and unlock more lending opportunities with alternative data.
We believe in the power of data and analytics
to manage risk & uncover opportunity.
Products You May Be Interested In
-
Business Data Enrichment Suite
Optimize customer data to identify opportunities and avoid risk
Learn More -
LexisNexis® RiskView™ Intentional Misuse
RiskView Intentional Misuse equips you with the targeted insights you need to support more confident lending decisions
Learn More -
LexisNexis ® RiskView™ Credit Solutions
Improve consumer credit risk assessment with LexisNexis RiskView Credit Solutions
Learn More -
LexisNexis® RiskView™ Optics and RiskView™ Spectrum Scores
Improve risk assessment performance across the credit spectrum
Learn More -
RiskView Attributes
Enhance risk modeling performance across the credit spectrum
Learn More -
RiskView™ Liens & Judgments Report
Retain your competitive edge without the added expense of recalibrating your models
Learn More -
LexisNexis® Small Business Attributes
Gain a clearer view of no-file or thin-file small businesses with alternative data attributes
Learn More -
LexisNexis® Small Business Credit Report
Uncover risk and opportunity in small business with LexisNexis® Small Business Credit Report
Learn More -
LexisNexis® Small Business Monitoring
Proactively monitor the changes across your portfolio to tap into new opportunities and avoid unforeseen risk
Learn More